Idea
No Free Lunch Theorem argues that without having substantive information about the modeling problem, there is no single model that will always do better than any other model. Because of this, a strong case can be made to try a wide variety of techniques, then determine which model to focus on.
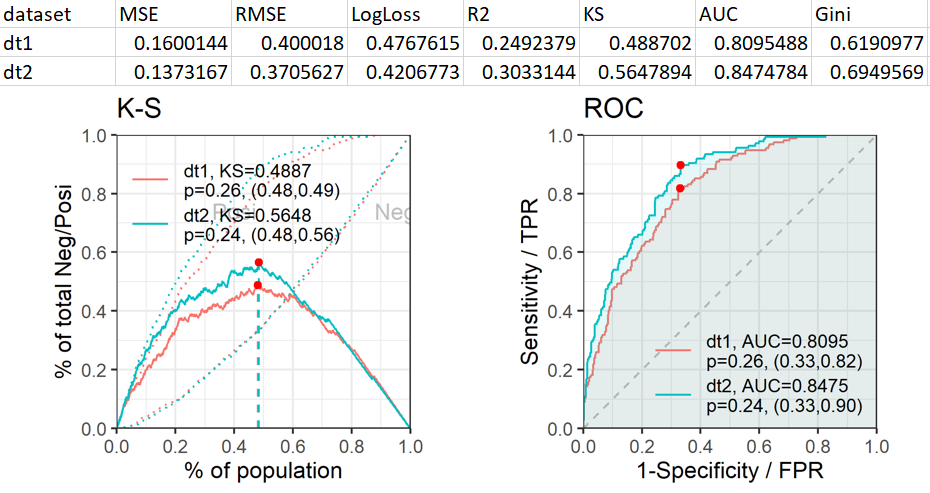
Kolmogorov-Smirnov Test (KS Test) of normality
• Examining 3 data samples (dt1-3) to see if it is a
form of normal distribution
• Useful tool to quickly determine (when working with big data) whether the sample data are randomly obtained from a normally distributed population.
• If p-value is >0.05 then data is normally distributed.
Receiver Operating Characteristic (ROC)
• Shows how well the model performs with all possible different thresholds (useful in comparing models), and trade-off between sensitivity and specificity.
• The size of the area indicates how well the model’s scoring does at separating 2 classes (bigger is better).
• Classes are True Positive Rate (TPR) and False Positive Rate (FPR).
• Perfect classifier has Area Under the Curve (AUC) of 1.0, which would mean that all positive examples have higher scores than any negative examples.
• Very useful for credit rating model valuation and fraud detection
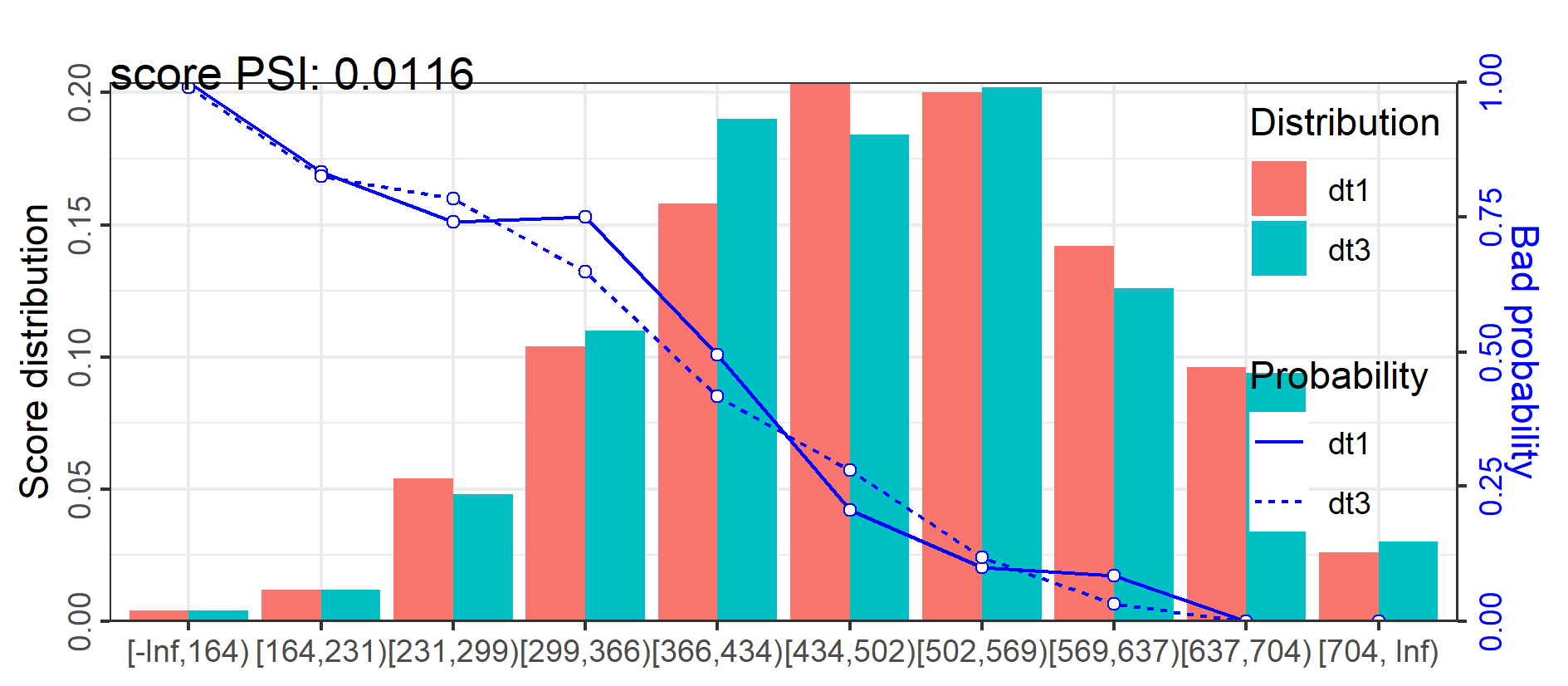
Population Stability Index (PSI)
• Comparison of distributions of training data (data used to develop the model) to a scoring variable (predicted probability)
• PSI that’s lower than 0.1 indicates that model does not need any adjustment / change. If PSI is greater than 0.1 then adjustment is required.
Category
- Multi-model approach, Machine Learning, Descriptive statistics
